Abstract
Approximate memories reduce power and increase energy efficiency, at the expense of errors in stored data. These errors may be tolerated, up to a point, by many applications with negligible impact on the quality of results. Uncontrolled errors in memory may, however, lead to crashes or broken outputs. Error rates are determined by fabrication and operation parameters, and error tolerance depends on algorithms, implementation, and inputs. An ideal configuration features parameters for approximate memory that minimize energy while allowing applications to produce acceptable results. This work introduces SmartApprox, a framework that configures approximation levels based on features of applications. In SmartApprox, a training phase executes a set of applications under different approximation settings, building a knowledge base that correlates application features (e.g., types of instructions and cache efficiency) with suitable approximate memory configurations. At runtime, features of new applications are sampled and approximation knobs are adjusted to correspond to the predicted error tolerance, according to existing knowledge and the current error scenario, in consonance with hardware characterization. In this work, we list and discuss sets of features that influence the approximation results and measure their impact on the error tolerance or applications. We evaluate SmartApprox on different voltage-scaled DRAM scenarios using a knowledge base of 26 applications, wherein energy savings of 36% are possible with acceptable output. An evaluation using a combined energy and quality metric shows that SmartApprox scores 97% of an exhaustive search for ideal configurations, with significantly lower effort and without application-specific quality evaluation.
Content

Presentation slides (to appear)
Link to conference proceedings (to appear)
Applications
The experimental evaluation of SmartApprox was performed with 26 applications on the knowledge base.
The following table contains the complete list of applications, their source, quality metric used, input workload, execution time with AxPIKE, and total instructions executed.
| application | benchmark | quality metric | input | exec. time (s) | total instructions |
|---|---|---|---|---|---|
| 2mm | Polybench [5] | MAPE | 32x32 double matrices | 46 | 8,62E+07 |
| atax | Polybench [5] | FEE | 500x500 double matrices | 43 | 6,72E+07 |
| blackscholes | AxBench [1] | MAPE | 1,000 entries | 45 | 8,20E+07 |
| bunzip2 | CBench [3] | SSI | compressed 256x256 image | 43 | 5,52E+07 |
| bzip2 | CBench [3] | SSI | 256x256 image | 109 | 1,11E+08 |
| correlation | Polybench [5] | FEE | 64x64 long int matrices | 26 | 4,77E+07 |
| covariance | Polybench [5] | FEE | 32x32 double matrices | 61 | 9,09E+07 |
| dijkstra | MiBench [4] | FEE | complete graph of 60 vertices | 18 | 3,37E+07 |
| fannkuch-redux | Benchmarks Game [2] | MAPE | N=9 | 64 | 1,29E+08 |
| fasta | Benchmarks Game [2] | FEE | N=50,000 | 10 | 2,15E+07 |
| fft | MiBench [4] | MAPE | Max waves 8, size 1024 | 82 | 1,56E+08 |
| floyd-warshall | Polybench [5] | FEE | complete graph of 64 vertices | 68 | 1,30E+08 |
| inversek2j | AxBench [1] | MAPE | 1,000 coordinates | 59 | 9,82E+07 |
| jacobi-2d-imper | Polybench [5] | FEE | Arrays of 32 double values | 36 | 6,39E+07 |
| jmeint | AxBench [1] | FEE | 1,0000 coordinates | 62 | 9,77E+07 |
| jpeg | AxBench [1] | SSI | 512x512 image | 127 | 2,30E+08 |
| k-nucleotide | Benchmarks Game [2] | MAPE | 2 sequences of 50,000 nucleotides | 121 | 9,79E+07 |
| mandelbrot | Benchmarks Game [2] | SSI | N=500 | 28 | 7,49E+07 |
| mm | MAPE | 100x100 int matrices | 42 | 8,01E+07 | |
| nbody | Benchmarks Game [2] | MAPE | N=100,000 | 35 | 6,48E+07 |
| pi | MAPE | N=1,000,000 | 17 | 3,53E+07 | |
| qsort | MiBench [4] | FEE | 10,000 strings | 36 | 6,68E+07 |
| reg_detect | Polybench [5] | MAPE | Iter=10,000, Length=32, MaxGrid=6 | 41 | 7,78E+07 |
| reverse-complement | Benchmarks Game [2] | FEE | 2 sequences of 50,000 nucleotides | 30 | 5,67E+07 |
| sobel | SSI | 256x256 image | 124 | 1,54E+08 | |
| spectralnorm | Benchmarks Game [2] | MAPE | N=500 | 48 | 1,26E+08 |
Benchmarks repositories:
[1] AxBench: http://axbench.org/
[2] Benchmarks Game: https://benchmarksgame-team.pages.debian.net/benchmarksgame/
[3] CBench: http://ctuning.org/cbench
[4] MiBench: http://vhosts.eecs.umich.edu/mibench/
[5] Polybench: https://web.cse.ohio-state.edu/~pouchet.2/software/polybench/
The source code of the applications are available at https://github.com/VArchC/apps
Quality Metrics
Quality metrics quantify how different is an approximate output compared to the accurate output. Thus, the quality metric is resulting from a comparison between the outputs of accurate and approximate executions of the same code with the same input. The quality metrics express how much the approximate output data array (F) deviates from an accurate output data array (A). Below, we show the quality metrics used for each application.
- Fraction of Equal Elements (FEE)
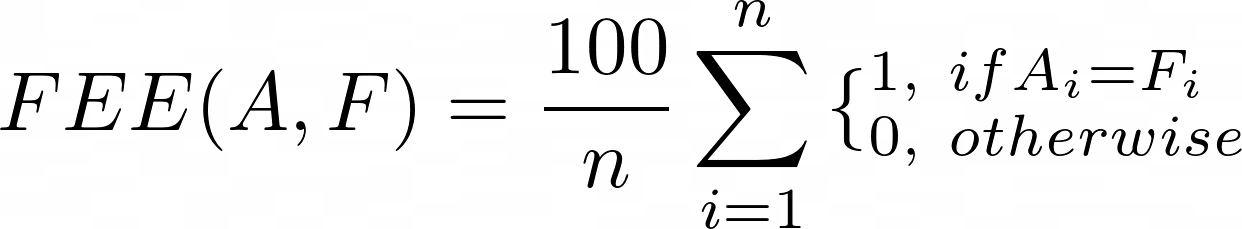
where:
n: the number of elements in the data array;
A_i: the i-th element in the accurate array;
F_i: the i-th element in the approximate array.
Mean Absolute Percentage Error (MAPE) - https://en.wikipedia.org/wiki/Mean_absolute_percentage_error
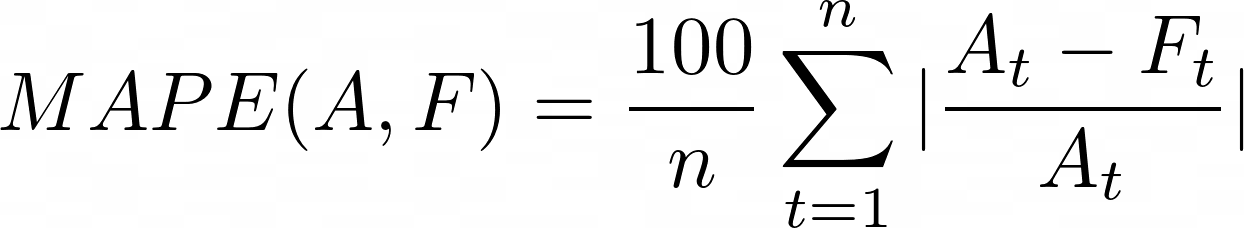
where:
n: the number of elements in the data array;
A_i: the i-th element in the accurate array;
F_i: the i-th element in the approximate array.
- Structural Similarity Index (SSI) - http://doi.org/10.1109/TIP.2003.819861 , https://en.wikipedia.org/wiki/Structural_similarity
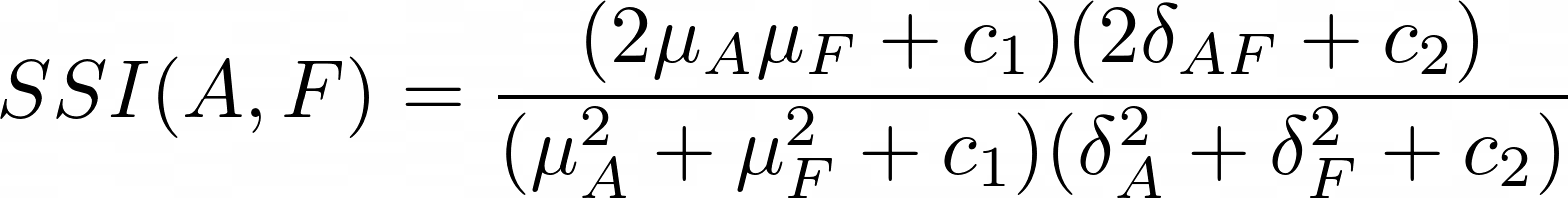
where:
μ_x: the average of the array x;
δx^2: the variance of the array x;
δ{xy}: the covariance of x and y;
c_1 = (k_1L)^2, c_2=(k_2L)^2 : two variables to stabilize the division with weak denominator;
L: the dynamic range of the pixel values (typicaly 2^{#bits per pixel} - 1);
k_1 = 0.01 and k_2=0.03.
Cite us
@INPROCEEDINGS{SmartApprox-IGSC2021,
author={Jo\~ao {Fabr\'icio Filho} and Isa\'ias Felzmann and Lucas Wanner},
booktitle={12th International Green and Sustainable Computing Conference (IGSC)},
title={{SmartApprox: learning-based configuration of approximate memories for energy-efficient execution,}},
year={2021}
}